
こんばんは、しーまんです。
Snowflakeでは外部のデータをロードすることでその恩恵を最大限活かすことができます。
今回はS3に配置されたCSVのデータをSnowflake上にロードする方法を紹介していきます。
外部連携周りの設定で苦労されている方の参考になりましたら幸いです。
テーブル作成方法
Snowflakeでのテーブル作成や権限周りについては別記事に公開しておりますので、こちらを参照ください。

データロード設定
SnowflakeにS3からデータをロードするためにはストレージ統合を行う必要があります。
他にも設定方法はありますが、ストレージ統合が一番セキュアですのでこちらの方法で設定することをおすすめします。
他の設定方法について知りたい場合はドキュメントを参考にしてください。
設定手順は以下の流れになります。
- インテグレーション作成
- ステージ作成
- AWSでIAMロール作成
ドキュメントではまず先に仮のIAMロールを作成してからインテグレーションを作成し、その情報を元にIAMロールの設定を変更しています。この手順でもよいのですが、SnowflakeとAWSを行ったりきたりしないといけないので、上記の手順にしてステップ数を減らしています。
インテグレーション
ではまずステップ1.インテグレーションの設定をしていきましょう。
作成時に予め決めておく必要があるのは後ほど作成する「IAMロール名」と「接続するバケット名」になります。
それぞれ「storage_aws_role_arn」と「storage_allowed_locations」に設定しましょう。
※ 許可するバケットは複数設定可能です。
-- アカウントを操作できるロールに変更.
use role accountadmin;
--s3連携 development
create storage integration test_s3_int
type = external_stage
storage_provider = s3
enabled = true
storage_aws_role_arn = 'arn:aws:iam::<AWSアカウントID>:role/snowflake-role'
storage_allowed_locations = ('s3://test-bucket/');
-- 作成したインテグレーションの情報を取得.
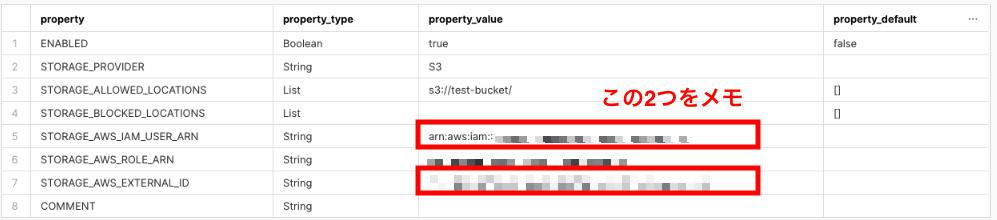
desc integration test_s3_int;作成したインテグレーションの情報をこの後のAWSのIAMロール作成時に使用します。
「STORAGE_AWS_IAM_USER_ARN」と「STORAGE_AWS_EXTERNAL_ID」の内容をメモしておきましょう。
ステージ作成
インテグレーションの作成が終わったら次はステージの作成です。
このステージオブジェクトを通してSnowflakeのテーブルにデータをロードします。
create or replace stage test_stage
storage_integration = test_s3_int
url = 's3://test-bucket/csv/';IAM Role作成
最後にAWS側でIAMロールの作成を行います。
IAMロールの作成方法はドキュメントどおりになります。
まずはポリシーを作成しその後ロールを作成していきます。
ロール作成時にインテグレーション作成時に設定した「IAMロール名」で作成するのと、「STORAGE_AWS_IAM_USER_ARN」「STORAGE_AWS_EXTERNAL_ID」をそれぞれ設定するのを忘れないようにしましょう。
これでデータをロードする設定が完了しました。
S3からデータロードをテストする
それでは先程設定したステージを使用して、テストテーブルにデータをロードしてみましょう。
データをロードするには「copy into <テーブル名> from @<ステージ名>/<ファイルパス> file_format …」でロードを行います。
今回は「s3://test-bucket/csv/test.csv」をtest_tableにロードする例になります。
copy into test_schema.test_table
from @test_stage/test.csv
file_format = (
type = csv
skip_header = 1
field_optionally_enclosed_by = '0x22'
);ファイルフォーマットがcsvで1行名はカラム名が入る想定なのでデータとしてはスキップしています。
またCSVのデータでtimestamp型のデータが「”(ダブルクウォート)」で囲まれているとテーブル定義と型が違うというエラーが出てしまうので、それを回避するためにfield_optionally_enclosed_byを設定しています。
エラーが出なければS3からSnowflakeへのデータロードが完了するはずです。
まとめ
今回はAWSのS3上に配置されたCSVファイルからSnowflakeにデータをロードする方法を解説いしました。
ストレージの連携にはいくつか手順が必要ですが、1度設定してステージを汎用的に利用すれば外部ストレージのデータを簡単にロードすることが可能です。
Snowflakeを使用する上で外部ストレージとの連携は必須ですので、ぜひ連携方法についてはおさえておきましょう!!
以上、Snowflakeの外部連携について参考になれば幸いです。


コメント